开源监控框架:LinkedIn Kafka Monitor
摘要
- 一、How Kafka Works
- 二、Kafka Application:基于 Kafka 构建事件溯源模式的微服务
- 三、Kafka Operation:LinkedIn 开源 Kafka Monitor
一个关于Kafka的监控测试框架
Apache Kafka 已经成为了一个面向大规模流数据的,标准的消息系统。在Linkedin这样的公司,它被用作各类数据管道的主力,支持一系列关键服务。它已经成为确保企业基础架构健壮、容错和高性能的核心组件。
在过去,网站高可用工程师(SRE)必须依赖Kafka服务器的报告来度量、监控一个Kafka集群(例如,访问流量,离线分区计数,under-replicated分区计数,等等)。如果任何一个指标不可用,或者任何指标的值是异常的,都有可能是某些方面出错了,SRE则 需要介入问题排查。然而,从一个Kafka集群获得这些指标并不像听起来那么容易—无论集群是否可用,一个很低的流入流出值并不没有必要告诉我们,也不能为最终用户提供一个基于可用性经验的、细粒度的参考结果(比如说,在这个事件中描述道:只是一个分区的子集异常了)。随着我们的集群增长得愈加庞大,为越来越多的重要业务提供服务,可靠、精确地度量Kafka集群可用性的能力,也就变得越来越重要。
为了监控可用性,有必要主干的稳定性,从功能上或性能方面尽可能早的捕获可回溯的信息。Apache Kafka 在虚拟机中包含一系列单元测试和系统测试方法,用于检测错误。到目前为止,我们仍然能发现一些偶发错误,它们直到Kafka在真实的集群中已经部署很多天甚至几周之后才显现。这些错误会引起许多运行时开销或者导致服务中断。有些时候该问题很难被重现,SRE工程师只能在开发者找到原因之前回退到上一个版本,这显然要增加Kafka的部署和维护成本。在许多情况下,这些错误可以在更早的阶段就被探查出来,假如我们可以在一个具备多样化故障转移的环境部署Kafka,同时加载生产规模的流量、延长持续时间。
Kafka Monitor 是一个监控测试Kafka部署情况的框架,可以帮助我们针对上面的不足提供以下能力:
- (a)在生产集群持续监测SLA
- (b)在测试集群持续进行回归测试。 在最近的 KafkaSummit 我们已经宣布在 Github上开源 Kafka Monitor。接下来我们将继续开发 Kafka Monitor 并把它作为我们事实上的Kafka认证解决方案。我们希望它也能使别的公司从中收益,那些希望验证和监控它们自己的Kafka部署情况的公司。
设计概览
Kafka Monitor 使得这些事情变得很容易: 在真实的生产集群中,开发和执行长时间运行特定的Kafka系统测试,基于用户提供的SLA监控已经部署的Kafka。
开发者可以创建新的测试,通过组装可复用的组件,用来仿真各种各样的场景(例如 GC 中断,代理被硬杀,回滚,磁盘故障,等等),收集指标;用户可以运行 K afka Monitor测试用例,在这些场景执行的时候可以伴随用户定义的定时任务,无论是测试集群还是生产集群,都能够验证,Kafka在这些场景下,是否能够达到预期效果。 为了实现上述目标,Kafka Monitor 的设计模型包含一系列测试结果收集器和服务。
一个Kafka Monitor 实例运行在一个单独的Java进程,在相同的进程里可以再产生多个测试用例和服务。下面的示意图表达了服务,测试用例和Kafka Monitor实例之间的关系,也可以知道Kafka Monitor 如何在Kafka集群和用户之间相互作用。
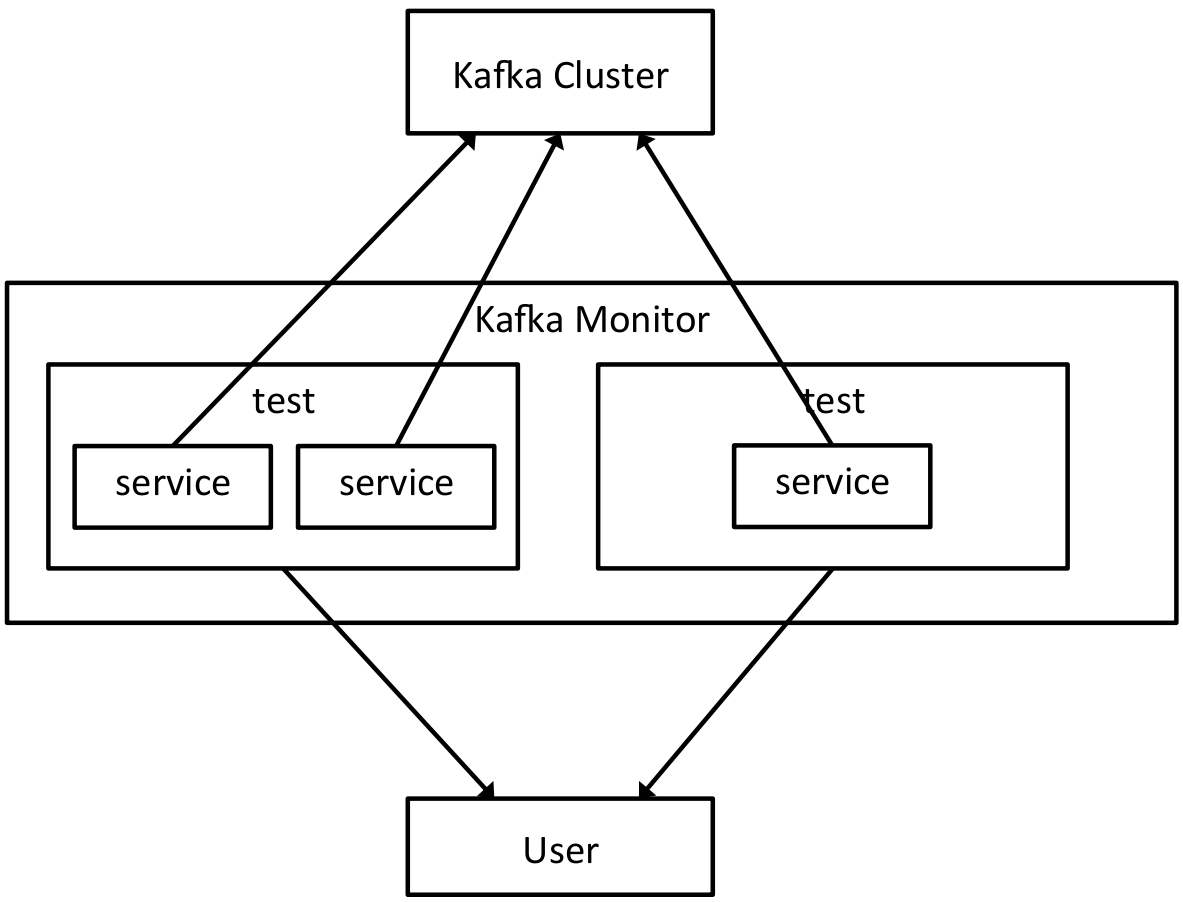
测试
一个典型的测试,将仿真一系列场景,基于某些前期已经定义的定时任务,需要启动一些生产者/消费者,上报指标,验证指标值是否符合前期定义的断言。举个例子,Kafka Monitor 能够启动一个生产者,一个消费者,每五分钟反射一个随机代理(比方说,如果说它是监控一个测试集群)。Kafka Monitor 接下来就可以度量可用性,消息丢包率,揭露JMX指标,用户可以在一个实时的健康仪表盘看到这些信息。 如果消息丢包率比一些阀值还要大,它能发出告警,这些阀值基于用户特定的可用性模型确定。
服务
我们概括了仿真逻辑,针对持续长时间场景的服务,目的是为了加快、简化从复用组件组装测试的过程。 一个服务将再产生它自己的线程,去执行那些场景、测量指标。举例说明,我们现在已经具备如下服务:
- [ ] 生产者服务,生成Kafka消息,测量生产速率和可用性指标。
- [ ] 消费者服务,消费Kafka消息,测量消息丢包率,消息复制速率以及端到端时延。这些服务依赖于生产者服务来提供消息,它会嵌入一个消息序列号和时间戳。
- [ ] 代理反射服务,能够基于预定义的定时任务提供一个发射代理。
一种测试需要由许多服务组成,验证一系列超时场景。举例来说,我们可以创建一个测试,包含一个生产者服务,一个消费者服务,以及一个代理反射服务。这个生产者服务和消费者服务,将被配置为从同一个主题发送和接收消息。那么这个测试将验证消息丢包率持续为0。
使用多个Kafka Monitor实例进行集群间性能测试
当所有的服务和相同的Kafka Monitor实例必须运行在同一个物理机器上的时候,我们可以启动多个Kafka Monitor 实例在不同的集群, 一起协作完成一个精密控制的端到端测试。在下面这个测试示意图中,我们启动了两个Kafka Monitor 实例在两个集群中。 第一个Kafka Monitor 实例包含一个生产者服务,提供给Kafka 集群1。消息从集群1反射到集群2。 最后,在第二个Kafka Monitor 实例的消费者服务,处理了消息,来自集群2中的同一个主题,并且报告了通过集群通道的端到端时延。

Kafka Monitor 在LinkedIn的应用
监控Kafka集群部署情况 在2016年早些时候,我们部署了Kafka Monitor用来监控可用性和端到端时延,包括LinkedIn的每一个Kafka集群。 本项目的 wiki 展示了更多细节,以及这些指标是如何度量的。这些基本但是关键的指标,对于积极地监控我们Kafka集群的SLA非常有用。
在端到端工作流中验证客户端库 正如早先发布的一篇BLOG中说明的那样,我们有一个客户端的库,缠绕在普通的Apache Kafka生产者和消费者, 用于提供一些 Apache Kafka 无法支持的特性,例如Avro编码,审计和大消息支持。我们也有一个REST客户端, 它允许非JAVA应用程序从Kafka生产和消费数据。这些客户端库和每一个新的Kafka release版本,验证它们的功能可用性是非常重要的。 Kafka Monitor允许用户将客户端库作为插件,加入到它的端到端工作流中。我们已经部署的Kafka Monitor实例, 已经在测试中使用我们封装的客户端和REST客户端,用于验证它们的性能和功能,使得这些客户端库和Apache Kafka的每一个新的release版本都能符合要求。
验证Apache Kafka新的内部Release版本 我们通常每个季度都会从Apache Kafka的主干版本复制代码,然后建立一个新的内部release版本,或者吸收Apache Kafka新的特性。 从主干复制代码的一个重要的收益就是,部署Kafka到LinkedIn的生产集群之后,通常能在Apache Kafka的主干版本上探查到一些问题, 这样的话我们就能在Apache Kafka 官方正式的release发布之前获得修复。 基于复制Apache Kafka主干版本可能存在的风险,我们做了额外的工作,在一个测试集群中验证每个内部release版本—从生产集群中获得镜像流量—几周以前生产环境部署新的release。 举例来说,我们执行回退或者硬杀掉代理的时候,需要检查JMX指标去验证确实有一个控制进程并且没有离线分区,为了验证Kafka在故障迁移场景中的可用性。 在过去,这些步骤都是手工进行的,非常消耗时间,并且我们有大量事件和许多场景需要测试,这种方式的伸缩性就非常差。我们切换到Kafka Monitor之后, 这个过程就自动化了,并且可以覆盖更多故障迁移的场景,而且是可以持续进行的。
相关工作的比较
Kafka Monitor 对其它公司而言也是有用的,可以帮助验证他们自己的客户端库和Kafka集群。 当然 Microsoft 也已经在 Github 上有了一个开源项目,也是监控室Kafka集群的可用性和端到端时延。 同样地,在这篇发表的博客中,Netflix介绍了一种监控服务,即发送持续的心跳消息,同时度量这些消息的时延。 Kafka Monitor自己的特点就是专注于可扩展性,模块化以及客户端库和多样化场景支持。
开始
Kafka Monitor的源代码可以从 Github 下载,基于Apache 2.0 授权协议。使用指南,设计文档和未来规划在README文件和项目wiki中可以查阅。我们很乐于听到你对该项目的反馈意见。当Kafka Monitor被设计用来作为,测试和监控Kafka部署情况的框架的时候,我们视线了一个基本的但是有用的测试,确保你能开箱即用。这些测试可以度量可用性,端到端时延,消息丢包率以及消息复制速率,通过运行一个生产者和一个消费者,它们使用同一个主题生产/处理消息。你可以在终端看到这些指标,基于HTTP GET请求、程序化地获得它们的值,甚至随着时间查看它们的值,通过一个简单(快速启动)的图形界面,如下面的截图所示。关于如何运行测试、查看指标的详细介绍内容请参阅项目网站。
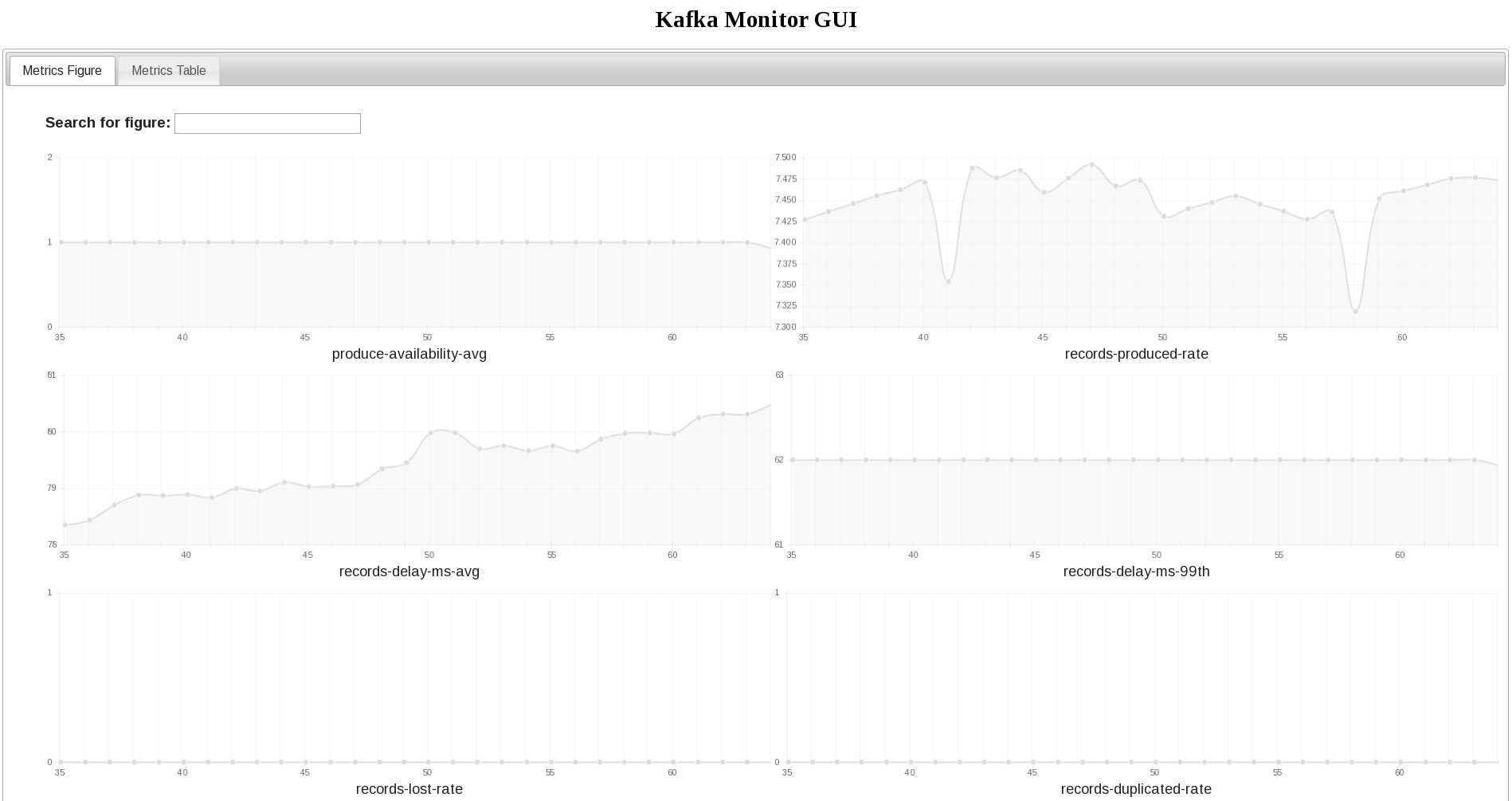
演进规划
增强测试场景 每次执行代码 check-in 的时候,Apache Kafka 包含了一大批系统测试。我们计划在Kafka Monitor中实现一个简单的测试, 然后部署到LinkedIn的测试集群,最终做到持续运行这些测试。这使得我们可以在问题发生的时候进行性能回溯, 还可以验证各种特性的是否可用,例如限额、管理操作,授权,等等。
整合Graphite和类似的框架 它对用户来说非常有用,可以在他们的组织内,通过一个简单的 web 服务查看所有跟 Kafka 相关的指标。我们计划在 Kafka Monitor 中提升现有的报表服务,这样用户就能够导出 Kafka Monitor 的指标到 Graphite 或者他们选择的其它框架
整合故障注入框架 我们也计划将 Kafka Monitor 与故障注入框架整合(名叫 Simoorg),可以测试、收集Kafka在更全面的故障迁移场景中的处理能力,例如磁盘故障或者数据错误。
扩展阅读:开源架构技术漫谈
- Stack Overflow:2017年最赚钱的编程语言
- 玩转编程语言:构建自定义代码生成器
- 远程通信协议:从 CORBA 到 gRPC
- 基于Kafka构建事件溯源型微服务
- LinkedIn 开源 Kafka Monitor
- 基于Go语言快速构建一个RESTful API服务
- 应用程序开发中的日志管理(Go语言描述)
- 数据可视化(七)Graphite 体系结构详解