基于Ganglia实现集群性能态势感知
本文以开源项目Ganglia为例,介绍多集群环境下,利用监控系统进行故障诊断、性能瓶颈分析的一般方法。
回顾
通过前面的发布过的两篇文章,我们已经大致掌握了描述单个服务器的性能情况的方法。可以从load avgerage等总括性的数据着手,获得系统资源利用率(CPU、内存、I/O、网络)和进程运行情况的整体概念。参考CPU使用率和I/O等待时间等具体的数字,从而自顶向下快速排查各进程状态。也可以在60秒内,通过运行以下10个基本命令,判断是否存在异常、评估饱和度,度量请求队列长度等等。
在真实的工程实践中,并不能总是通过几行简单的命令,直接获得性能问题的答案。一般不会存在一台单独运行的服务器,它们一定属于某个服务集群之中,就算是同一集群的服务器,也可能属于不同建设周期、硬件配置不同、分工角色不同。或者由不同机房、不通集群的服务器共同协作完成任务。
另外,很多性能问题也需要长时间的追踪、对比才能作出判断。正如任何一个高明的医生,都需要尽可能多地了解、记录病人的病史,不掌握这些情况,盲目下药,无异于庸医杀人。诚如医者曰:
夫经方之难精,由来尚矣。今病有内同而外异,亦有内异而外,
故五脏六腑之盈虚,血脉荣卫之通塞,固非耳目之所察,
必先诊候以审之。世有愚者,读方三年,便谓天下无病可治;
及治病三年,乃知天下无方可用。
基于Ganglia项目,我们可以快速搭建一套高性能的监控系统,展开故障诊断分析、资源扩容预算甚至故障预测。
Ganglia框架简析
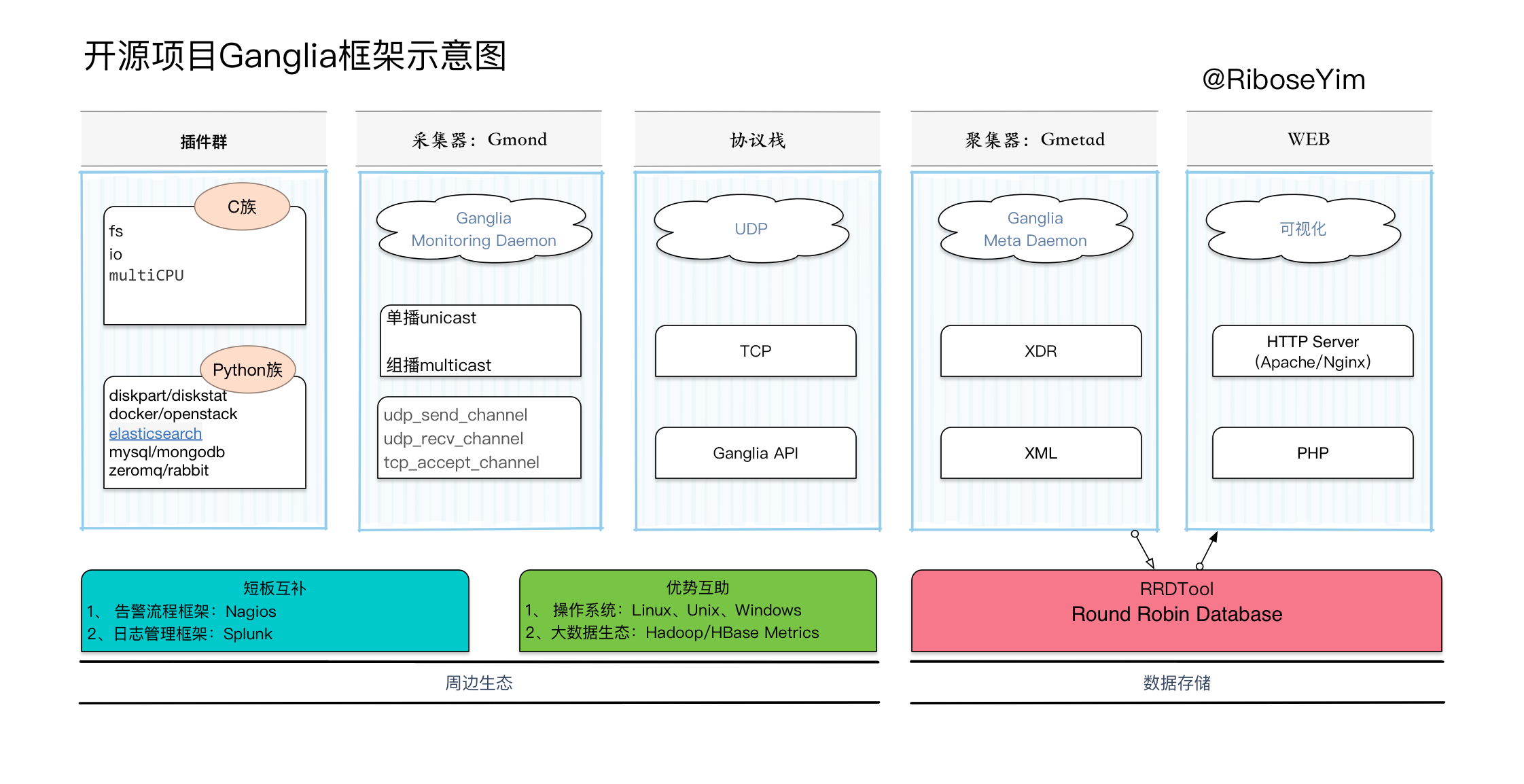
一般应用中,需要用到两个核心组件:
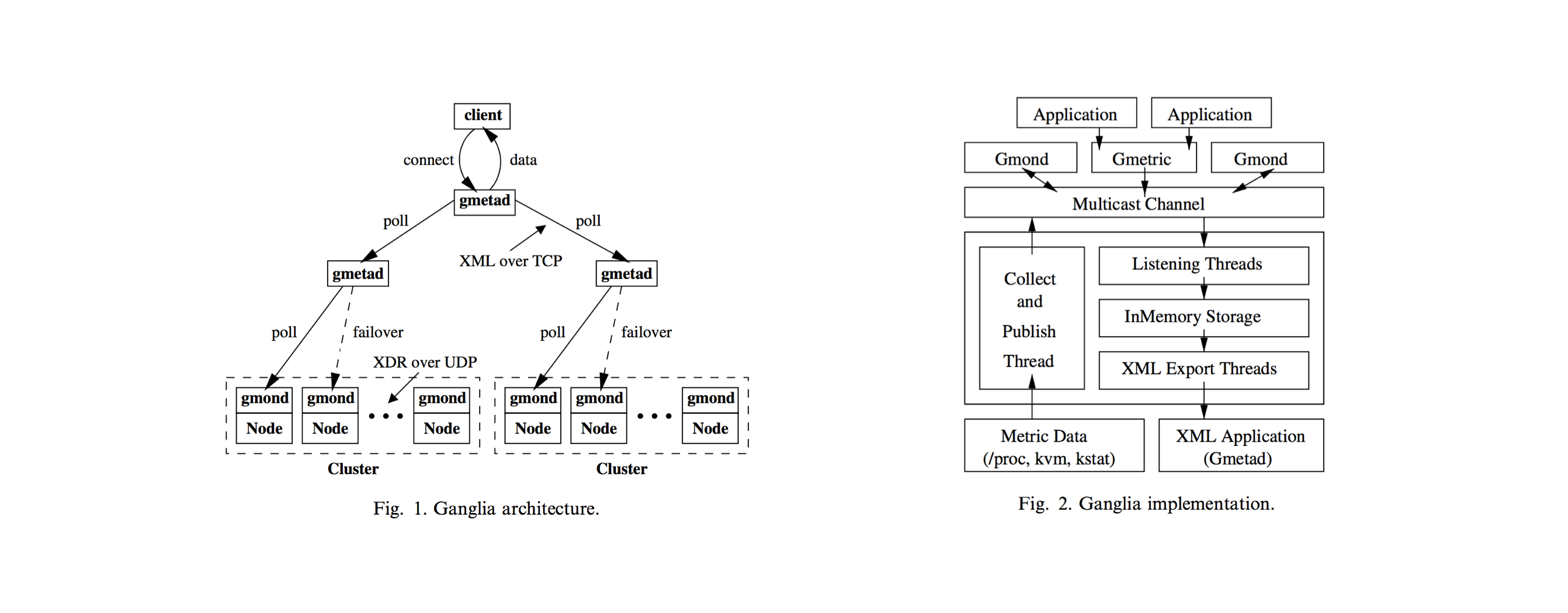
Gmond (Ganglia Monitoring Daemon) Gmond承担双重角色:1、作为Agent,部署在所有需要监控的服务器上。 2、作为收发机,接收或转发数据包。
Gmetad (Ganglia Meta Daemon) 负责收集所在集群的数据,并持久化到RRD数据库。根据集群的组网情况,可以部署1-N个。
Web frontend Ganglia项目提供一个PHP编写的通用型的Web包,主要实现数据可视化,能提供一些简单的数据筛选UI。页面不多,大量使用了模版技术。HTTP Server方面,用Apache和Nginx都可以。
RRDTool (Round Robin Database) Gmetad收集的时间序列数据都通过RRD存储,RRDTool作为绘图引擎使用。
插件生态 Ganglia最重要的特性之一就是提供了一个灵活的数据标准和插件API。 它使得我们可以根据系统的情况,很容易地在默认的监控指标集之上,引用或定制其他扩展指标。 这一特性在大数据领域也获得了认可,Hadoop,Spark等都开放了面向Ganglia的指标集。 在Github上也有很多现成的扩展插件。
Ganglia工作模式
项目的名称其实已经反映了作者的设计思路。 Ganglia(又作:ganglion),直译为“神经节”、“中枢神经”。在解剖学上是一个生物组织丛集,通常是神经细胞体的集合。在神经学中,神经节主要是由核周体和附随连结的树突组合而成。神经节经常与其他神经节相互连接以形成一个复杂的神经节系统。神经节提供了身体内不同神经体系之间的依靠点和中介连结,例如周围神经系统和中枢神经系统。
Ganglia的作者意图将服务器集群理解为生物神经系统,每台服务器都是独立工作神经节,通过多层次树突结构连接起来, 既可以横向联合,也可以从低向高,逐层传递信息。具体例证就是Ganglia的收集数据工作可以工作在单播(unicast)或多播(multicast)模式下, 默认为多播模式。
单播:Gmond收集到的监控数据发送到特定的一台或几台机器上,可以跨网段
多播:Gmond收集到的监控数据发送到同一网段内所有的机器上,同时收集同一网段内的所有机器发送过来的监控数据。 因为是以广播包的形式发送,因此需要同一网段内。但同一网段内,又可以定义不同的发送通道。
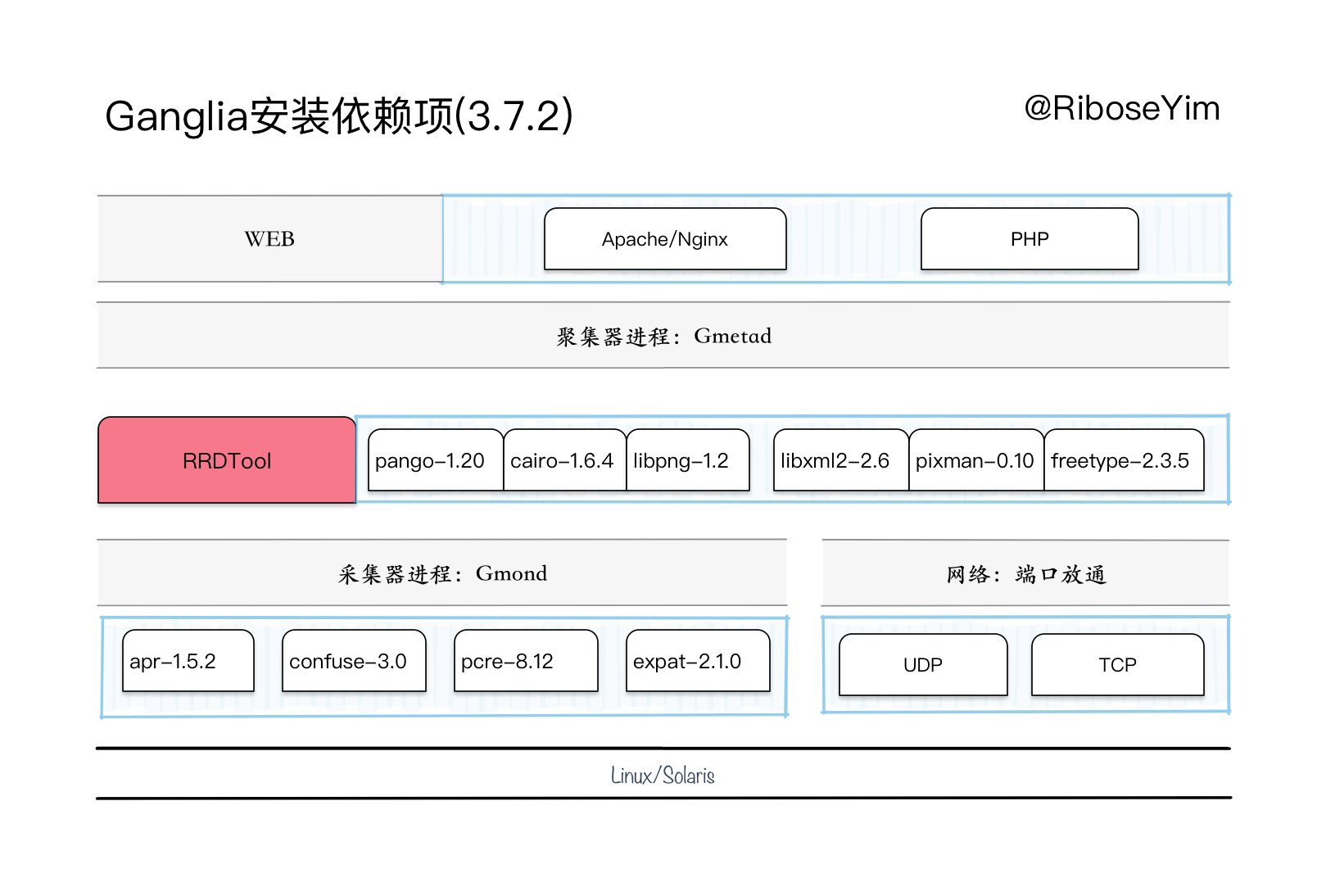
vi /usr/local/ganglia/etc/gmond.conf
默认配置:
cluster {
name = "cluster01"
}
udp_send_channel {
mcast_join = 239.2.11.71
port = 8649
ttl = 1
}
udp_recv_channel {
mcast_join = 239.2.11.71
port = 8649
bind = 239.2.11.71
retry_bind = true
}
tcp_accept_channel {
port = 8649
gzip_output = no
}
单播模式Gmetad增加配置:
udp_recv_channel {
port = 8666
}
单播模式Gmond增加配置:
udp_send_channel {
host = 192.168.0.39
port = 8666
ttl = 1
}
默认装载指标集:
modules {
module {
name = "core_metrics"
}
module {
name = "cpu_module"
path = "modcpu.so"
}
module {
name = "disk_module"
path = "moddisk.so"
}
module {
name = "load_module"
path = "modload.so"
}
module {
name = "mem_module"
path = "modmem.so"
}
module {
name = "net_module"
path = "modnet.so"
}
module {
name = "proc_module"
path = "modproc.so"
}
module {
name = "sys_module"
path = "modsys.so"
}
}
vi /usr/local/ganglia/etc/gmetad.conf
### 配置数据源,可以多个
data_source "cluster01" localhost:8649
data_source "cluster02" 192.168.0.39:8666 192.168.0.48:8666
gridname "mygrid"
### 指定RRD数据路径
rrd_rootdir "/home/data/ganglia/rrds"
查看数据流向
# netstat -an | grep 86
tcp 0 0 0.0.0.0:8649 0.0.0.0:* LISTEN ##tcp_accept_channel
udp 0 0 192.168.0.45:52745 239.2.11.71:8649 ESTABLISHED ##组播
udp 0 0 239.2.11.71:8649 0.0.0.0:*
udp 0 0 0.0.0.0:8666 0.0.0.0:* ##udp_recv_channel
Gmetad所在位置,已经可以收到监控数据的服务器列表:
# telnet localhost 8649 | grep HOST
<HOST NAME="192.168.0.56" IP="192.168.0.56" TAGS="" REPORTED="1478226772" TN="6" TMAX="20" DMAX="86400" LOCATION="GZ" GMOND_STARTED="1477817579">
</HOST>
<HOST NAME="192.168.0.39" IP="192.168.0.39" TAGS="" REPORTED="1478226771" TN="7" TMAX="20" DMAX="86400" LOCATION="GZ" GMOND_STARTED="1477473541">
......
Gmond所在位置,收到的监控指标数据明细:
# telnet localhost 8649 | grep cpu_idle
telnet: connect to address ::1: Connection refused
<METRIC NAME="cpu_idle" VAL="96.7" TYPE="float" UNITS="%" TN="33" TMAX="90" DMAX="0" SLOPE="both">
<METRIC NAME="cpu_idle" VAL="100.0" TYPE="float" UNITS="%" TN="20" TMAX="90" DMAX="0" SLOPE="both">
<METRIC NAME="cpu_idle" VAL="91.2" TYPE="float" UNITS="%" TN="4" TMAX="90" DMAX="0" SLOPE="both">
<METRIC NAME="cpu_idle" VAL="96.3" TYPE="float" UNITS="%" TN="28" TMAX="90" DMAX="0" SLOPE="both">
<METRIC NAME="cpu_idle" VAL="99.9" TYPE="float" UNITS="%" TN="5" TMAX="90" DMAX="0" SLOPE="both">
<METRIC NAME="cpu_idle" VAL="83.9" TYPE="float" UNITS="%" TN="14" TMAX="90" DMAX="0" SLOPE="both">
<METRIC NAME="cpu_idle" VAL="84.2" TYPE="float" UNITS="%" TN="0" TMAX="90" DMAX="0" SLOPE="both">
<METRIC NAME="cpu_idle" VAL="44.1" TYPE="float" UNITS="%" TN="9" TMAX="90" DMAX="0" SLOPE="both">
......
数据可视化
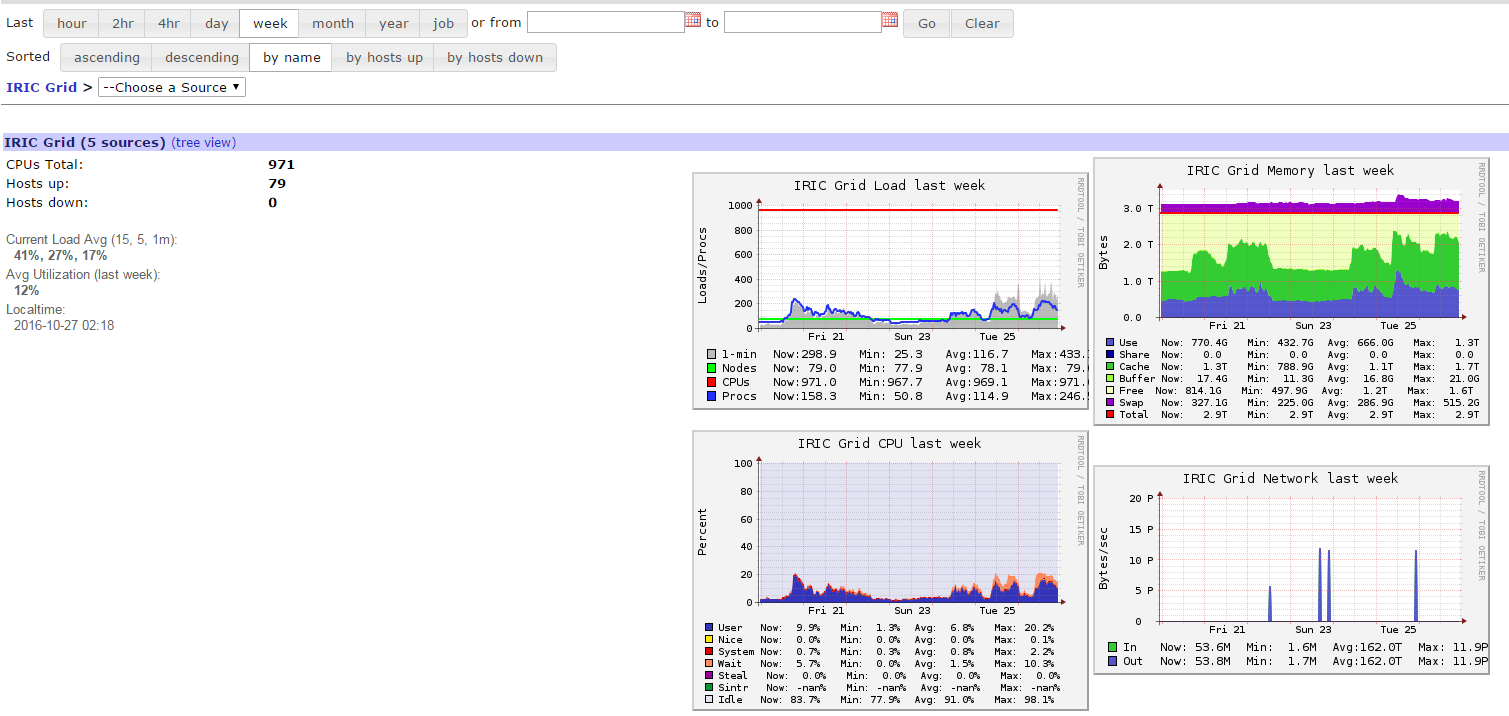
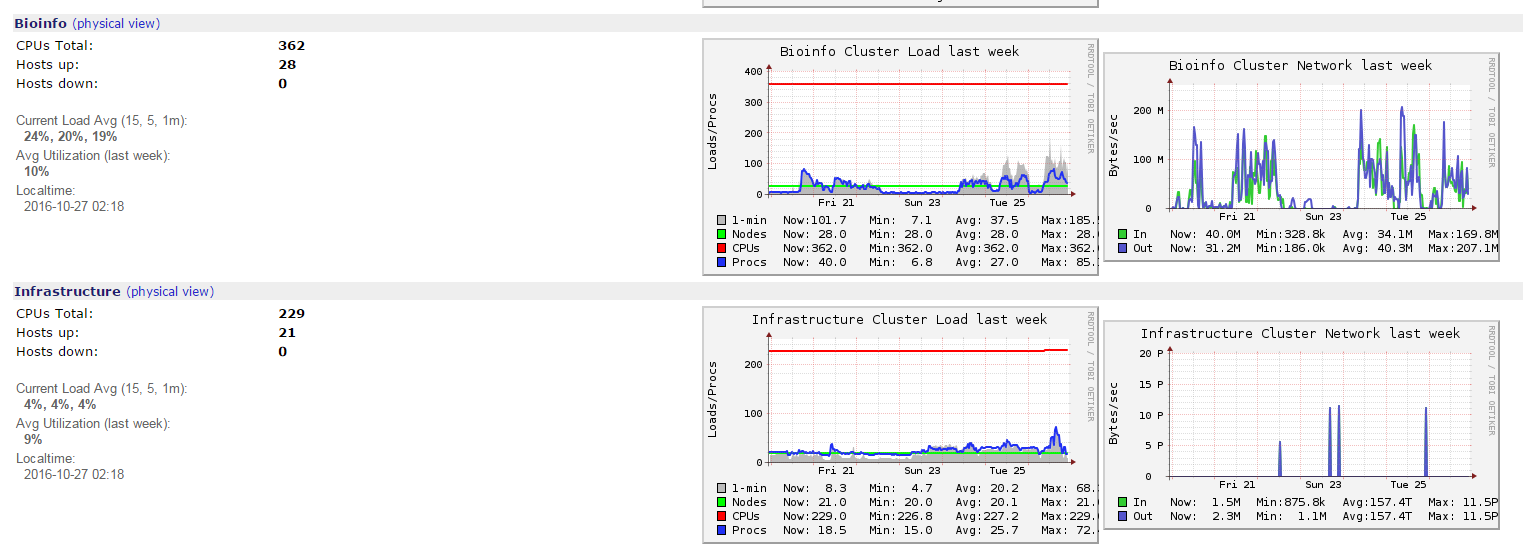

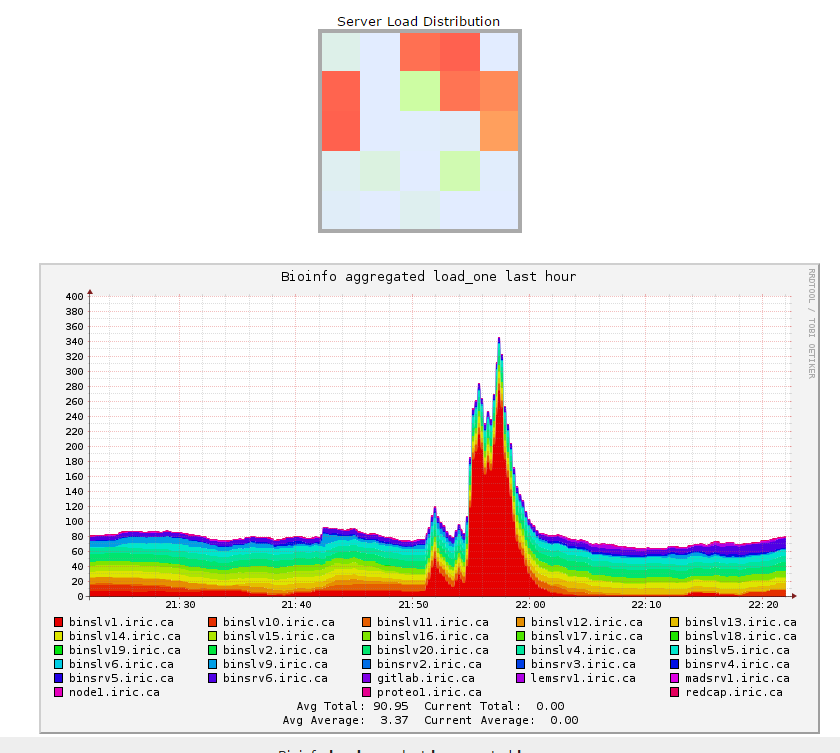
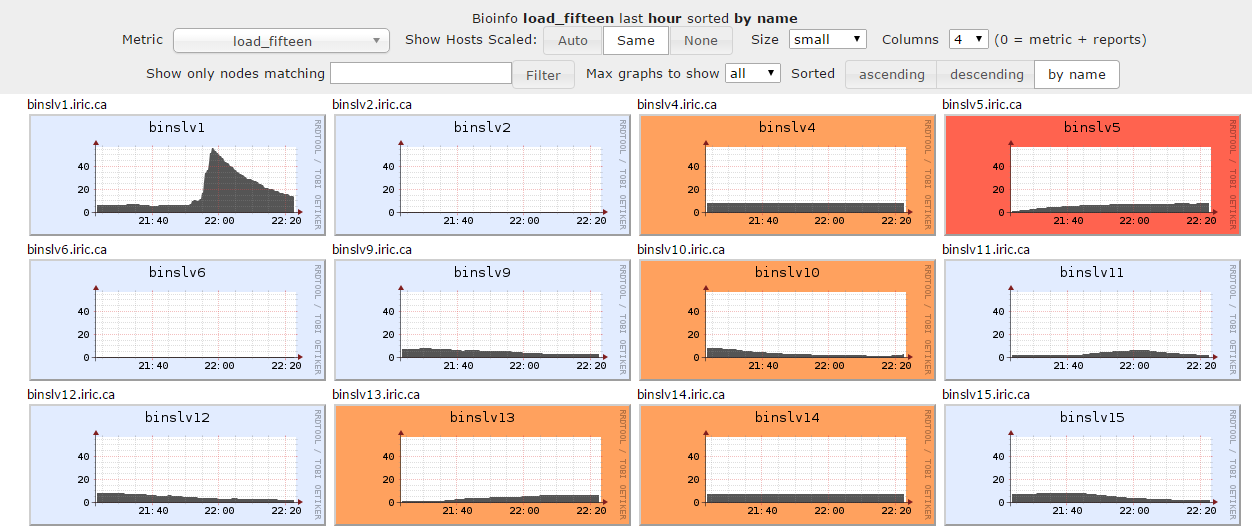

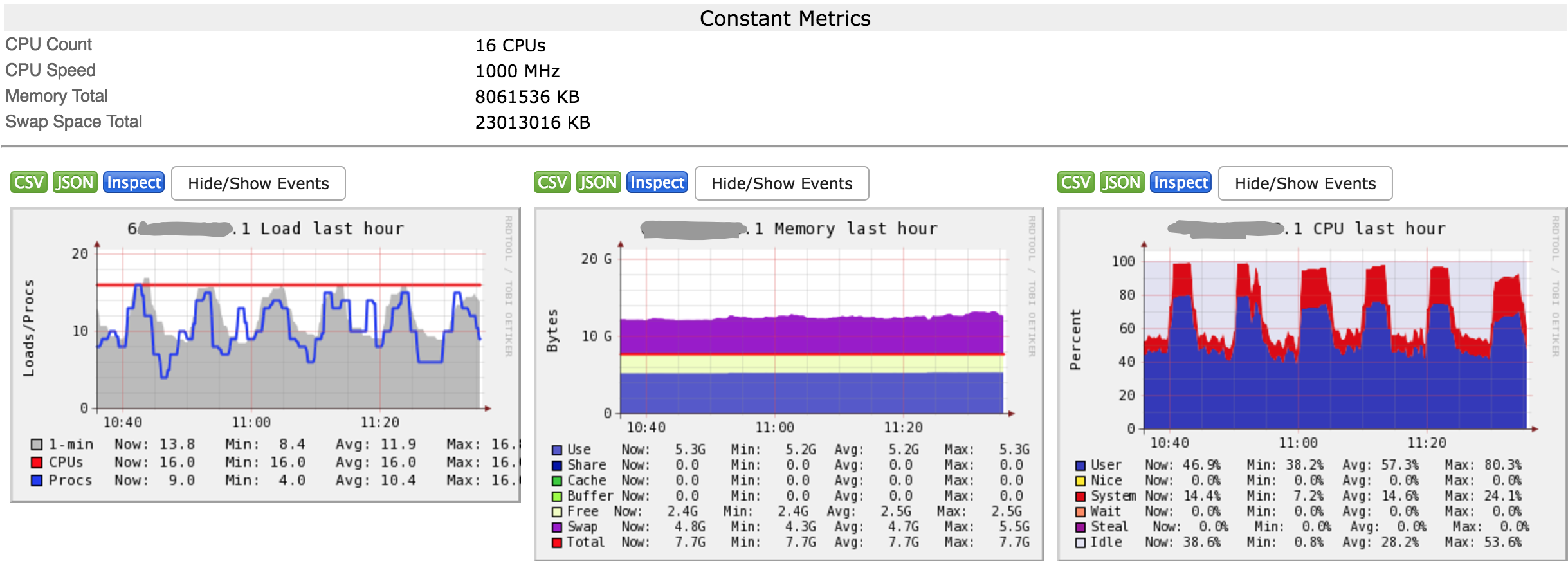
注意事项
没有任何一个开源项目是完美的。
1、告警流程框架:Ganglia本身并不具备,可以选用Nagios补充。
2、日志管理框架:Ganglia本身并不具备,可以选用Splunk补充。
3、性能开销预算
对于单纯的Gmond节点来说,性能开销很低。主要的瓶颈在中央节点。
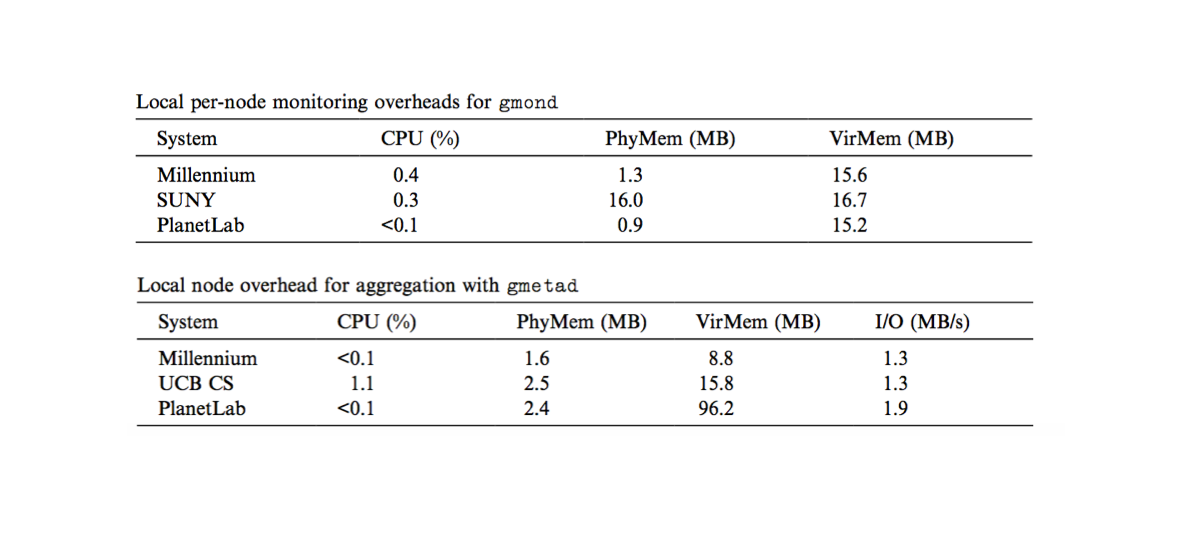
各节点的gmond进程向中央节点发送的udp数据带来的网络开销。如果一个节点每秒发10个包, 1000个节点将会发出10000个,每个包有200字节,就有2m字节,10000个包的处理所需要的cpu使用也会上升。
Gmetad默认15秒向gmond取一次xml数据,解析xml文件带来的CPU负荷也会随着管理节点数线性增长。
格外需要注意的是RRD的写入瓶颈。实际应用中需要根据资源情况,调整采样频率、权衡指标数量、引入RRDCached等方式优化。
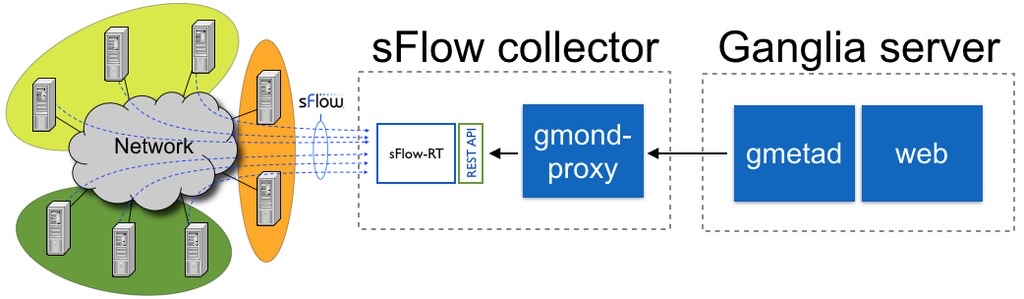
4、网络流向监控:Ganglia原生支持sFlow GitHub:gmond-proxy project。what are some of the benefits of using the proxy?
Firstly, the proxy allows metrics to be filtered, reducing the amount of data logged and increasing the scaleability of the Ganglia collector.
Secondly, sFlow-RT generates traffic flow metrics, making them available to Ganglia.
Finally, Ganglia is typically used in conjunction with additional monitoring tools that can all be driven using the analytics stream generated by sFlow-RT.
参考资料
1、《 The ganglia distributed monitoring system: design, implementation, and experience》(必读)

2、《Wide Area Cluster Monitoring with Ganglia》(必读)

3、这篇本来没有什么直接关系,是Ganglia作者的最新研究成果,仅供娱乐。

更多精彩内容,请扫码关注公众号:@睿哥杂货铺 RSS订阅 RiboseYim